Difference between revisions of "Manual Problem Grader"
Jump to navigation
Jump to search
| (One intermediate revision by the same user not shown) | |||
| Line 2: | Line 2: | ||
There is no configuration required to use this feature. When acting as a student, you can activate the manual problem grader by checking the box: |
There is no configuration required to use this feature. When acting as a student, you can activate the manual problem grader by checking the box: |
||
| − | [[File:ManualGraderEnable.png]] |
+ | [[File:ManualGraderEnable.png]] |
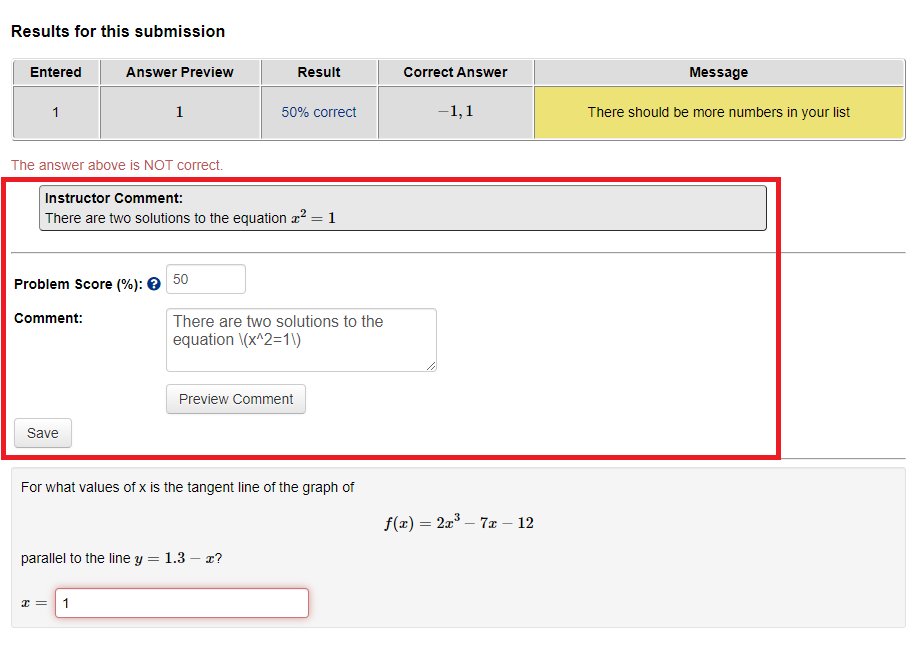
This will present you with text boxes to change the student's score and add a comment: |
This will present you with text boxes to change the student's score and add a comment: |
||
| − | [[File:ManualGraderComment.png]] |
+ | [[File:ManualGraderComment.png]] |
| − | [Category:Instructors] |
+ | [[Category:Instructors]] |
Latest revision as of 15:59, 15 April 2021
Version 2.16 introduces the Manual Problem Grader, which allows you to adjust a score for a student directly from the problem page, and also add comments for an individual student.
There is no configuration required to use this feature. When acting as a student, you can activate the manual problem grader by checking the box:
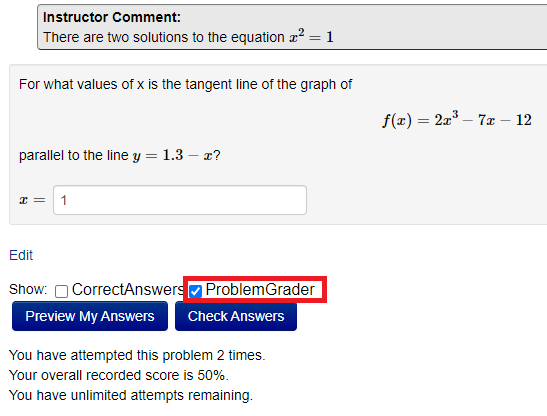

This will present you with text boxes to change the student's score and add a comment: